PyTorch 卷积神经网络
在本文中,使用 PyTorch 实现一个 卷积神经网络,完成手写数字识别任务。
Note
本实例来自《深度学习原理与PyTorch实战(第2版)》,本文是我对该节的自学实践。
输入图像为 (28, 28) 的灰度图像,每个元素的取值范围是 0~255。
卷积神经网络结构
整体结构如下:
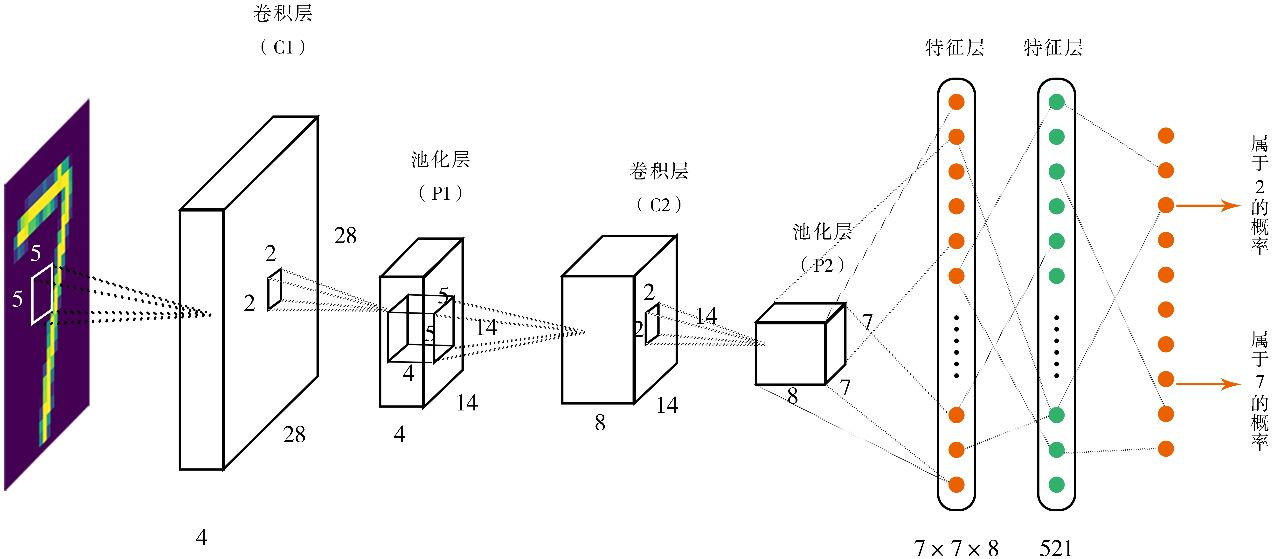
注:图片来自 《深度学习原理与PyTorch实战(第2版)》。
整体分为两个部分:
- 图像处理部分:左边 4 个盒子
- 前馈多层神经网络:右边的线性排布部分
整体过程的第一部分:
- 图像经过一层卷积运算,变成第一个盒子(
28, 28, 4),这实际上是 4 张(28, 28)图像 - 经过第一次池化,尺寸缩小了一半,变成 4 张
(14, 14)小图 - 进行第二次卷积运算,变成第二个盒子
(14, 14, 8),变成 8 张图了 - 进行第二次池化,尺寸又缩小一般,变成 8 张
(7, 7)小图
整体过程的第二部分:
- 将
(8, 7, 7)供 392 像素神经元拉伸为 392 长度的向量(前馈神经网络的输入部分) - 之后经过一层隐藏层
- 映射到输出单元,10 个区间为 0~1 的小数,表示 0~9 数字的概率。
取做大概率的数字,作为最终输出。
卷积
书中用《找你妹》这个游戏来介绍理解卷积,非常形象。推荐直接阅读原作。
卷积运算就是在原始图像中搜索与卷积核相似的区域,即用卷积核从左到右、从上到下地进行逐个像素的扫描和匹配,并最终将匹配结果表示成一张新的图像,通常称为特征图。
池化
池化是卷积神经网络中的一个重要步骤,它的主要目的是降低数据的维度,从而减少计算量,同时也能帮助防止过拟合。
手写数字识别器
前面是理论部分,从本节往后,进入书上案例的实践环节。书中本节配套代码位于这里。
首先是数据准备。手写数字识别器所需要的数据集为 MNIST,PyTorch 中自带该数据集。
导入包准备:
# 导入所需要的包,请保证torchvision已经在你的环境中安装好.
# 在Windows需要单独安装torchvision包,在命令行运行pip install torchvision即可
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
定义超参数:
# 定义超参数
image_size = 28 #图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 20 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
接下来加载数据集:
# 加载MINIST数据,如果没有下载过,就会在当前路径下新建/data子目录,并把文件存放其中
# MNIST数据是属于torchvision包自带的数据,所以可以直接调用。
# 在调用自己的数据的时候,我们可以用torchvision.datasets.ImageFolder或者torch.utils.data.TensorDataset来加载
train_dataset = dsets.MNIST(
root='./data', #文件存放路径
train=True, #提取训练集
#将图像转化为Tensor,在加载数据的时候,就可以对图像做预处理
transform=transforms.ToTensor(),
download=True) #当找不到文件的时候,自动下载
# 加载测试数据集
test_dataset = dsets.MNIST(
root='./data',
train=False,
transform=transforms.ToTensor())
# 训练数据集的加载器,自动将数据分割成batch,顺序随机打乱
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
将测试集分为两部分,一部分作为校验集,一部分作为测试集:
'''我们希望将测试数据分成两部分,一部分作为校验数据,一部分作为测试数据。
校验数据用于检测模型是否过拟合,并调整参数,测试数据检验整个模型的工作'''
# 首先,我们定义下标数组indices,它相当于对所有test_dataset中数据的编码
# 然后定义下标indices_val来表示校验集数据的那些下标,indices_test表示测试集的下标
indices = range(len(test_dataset))
indices_val = indices[:5000]
indices_test = indices[5000:]
# 根据这些下标,构造两个数据集的SubsetRandomSampler采样器,它会对下标进行采样
sampler_val = torch.utils.data.sampler.SubsetRandomSampler(indices_val)
sampler_test = torch.utils.data.sampler.SubsetRandomSampler(indices_test)
# 根据两个采样器来定义加载器,注意将sampler_val和sampler_test分别赋值给了validation_loader和test_loader
validation_loader = torch.utils.data.DataLoader(
dataset =test_dataset,
batch_size = batch_size,
sampler = sampler_val)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
sampler = sampler_test)
PyTorch 数据集工具包
- PyTorch dataset:对数据集的封装
- PyTorch dataloader:从数据集中批量加载数据
- PyTorch sampler:采样器,采样方法,顺序或者随机
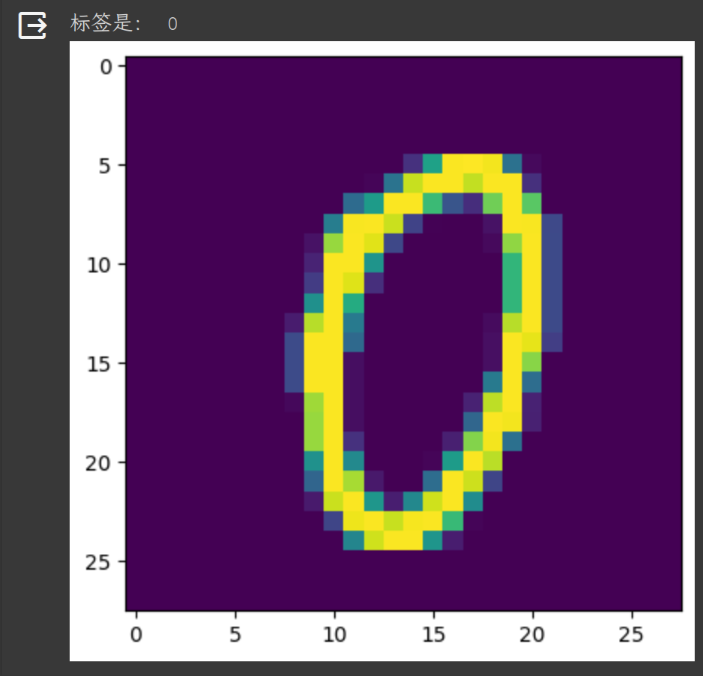
尝试绘制一张图片
#随便从数据集中读入一张图片,并绘制出来
idx = 1000
#dataset支持下标索引,其中提取出来的每一个元素为features,target格式,即属性和标签。[0]表示索引features
muteimg = train_dataset[idx][0].numpy()
#由于一般的图像包含rgb三个通道,而MINST数据集的图像都是灰度的,只有一个通道。因此,我们忽略通道,把图像看作一个灰度矩阵。
#用imshow画图,会将灰度矩阵自动展现为彩色,不同灰度对应不同颜色:从黄到紫
plt.imshow(muteimg[0,...])
print('标签是:',train_dataset[idx][1])
效果如下:
构建神经网络
构建神经网络 CovNet:
#定义卷积神经网络:4和8为人为指定的两个卷积层的厚度(feature map的数量)
depth = [4, 8]
class ConvNet(nn.Module):
def __init__(self):
# 该函数在创建一个ConvNet对象的时候,即调用如下语句:net=ConvNet(),就会被调用
# 首先调用父类相应的构造函数
super(ConvNet, self).__init__()
# 其次构造ConvNet需要用到的各个神经模块。
'''注意,定义组件并没有真正搭建这些组件,只是把基本建筑砖块先找好'''
#定义一个卷积层,输入通道为1,输出通道为4,窗口大小为5,padding为2
self.conv1 = nn.Conv2d(1, 4, 5, padding = 2)
#定义一个Pooling层,一个窗口为2*2的pooling运算
self.pool = nn.MaxPool2d(2, 2)
#第二层卷积,输入通道为depth[0], 输出通道为depth[1],窗口为5,padding为2
self.conv2 = nn.Conv2d(depth[0], depth[1], 5, padding = 2)
self.fc1 = nn.Linear(image_size // 4 * image_size // 4 * depth[1] , 512)
#一个线性连接层,输入尺寸为最后一层立方体的平铺,输出层512个节点
self.fc2 = nn.Linear(512, num_classes) #最后一层线性分类单元,输入为512,输出为要做分类的类别数
def forward(self, x):
#该函数完成神经网络真正的前向运算,我们会在这里把各个组件进行实际的拼装
#x的尺寸:(batch_size, image_channels, image_width, image_height)
#第一层卷积,激活函数用ReLu,为了防止过拟合
x = F.relu(self.conv1(x))
#x的尺寸:(batch_size, num_filters, image_width, image_height)
#第二层pooling,将图片变小
x = self.pool(x)
#x的尺寸:(batch_size, depth[0], image_width/2, image_height/2)
#第三层又是卷积,窗口为5,输入输出通道分别为depth[0]=4, depth[1]=8
x = F.relu(self.conv2(x))
#x的尺寸:(batch_size, depth[1], image_width/2, image_height/2)
#第四层pooling,将图片缩小到原大小的1/4
x = self.pool(x)
#x的尺寸:(batch_size, depth[1], image_width/4, image_height/4)
# 将立体的特征图Tensor,压成一个一维的向量
# view这个函数可以将一个tensor按指定的方式重新排布。
# 下面这个命令就是要让x按照batch_size * (image_size//4)^2*depth[1]的方式来排布向量
x = x.view(-1, image_size // 4 * image_size // 4 * depth[1])
#x的尺寸:(batch_size, depth[1]*image_width/4*image_height/4)
#第五层为全链接,ReLu激活函数
x = F.relu(self.fc1(x))
#x的尺寸:(batch_size, 512)
x = F.dropout(x, training=self.training) #以默认为0.5的概率对这一层进行dropout操作,为了防止过拟合
x = self.fc2(x) #全链接
#x的尺寸:(batch_size, num_classes)
x = F.log_softmax(x, dim = 0) #输出层为log_softmax,即概率对数值log(p(x))。采用log_softmax可以使得后面的交叉熵计算更快
return x
def retrieve_features(self, x):
#该函数专门用于提取卷积神经网络的特征图的功能,返回feature_map1, feature_map2为前两层卷积层的特征图
feature_map1 = F.relu(self.conv1(x)) #完成第一层卷积
x = self.pool(feature_map1) # 完成第一层pooling
feature_map2 = F.relu(self.conv2(x)) #第二层卷积,两层特征图都存储到了feature_map1, feature_map2中
return (feature_map1, feature_map2)
其中使用到了 dropout,来防止过拟合。
训练
def rightness(predictions, labels):
"""计算预测错误率的函数,其中predictions是模型给出的一组预测结果,batch_size行num_classes列的矩阵,labels是数据之中的正确答案"""
# 对于任意一行(一个样本)的输出值的第1个维度,求最大,得到每一行的最大元素的下标
pred = torch.max(predictions.data, 1)[1]
#将下标与labels中包含的类别进行比较,并累计得到比较正确的数量
rights = pred.eq(labels.data.view_as(pred)).sum()
#返回正确的数量和这一次一共比较了多少元素
return rights, len(labels)
net = ConvNet() #新建一个卷积神经网络的实例,此时ConvNet的__init__函数就会被自动调用
criterion = nn.CrossEntropyLoss() #Loss函数的定义,交叉熵
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) #定义优化器,普通的随机梯度下降算法
record = [] #记录准确率等数值的容器
weights = [] #每若干步就记录一次卷积核
#开始训练循环
for epoch in range(num_epochs):
train_rights = [] #记录训练数据集准确率的容器
''' 下面的enumerate是构造一个枚举器的作用。就是我们在对train_loader做循环迭代的时候,enumerate会自动吐出一个数字指示我们循环了几次
这个数字就被记录在了batch_idx之中,它就等于0,1,2,……
train_loader每迭代一次,就会吐出来一对数据data和target,分别对应着一个batch中的手写数字图,以及对应的标签。'''
for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环
data, target = data.clone().requires_grad_(True), target.clone().detach() #data为一批图像,target为一批标签
net.train() # 给网络模型做标记,标志说模型正在训练集上训练,
#这种区分主要是为了打开关闭net的training标志,从而决定是否运行dropout
output = net(data) #神经网络完成一次前馈的计算过程,得到预测输出output
loss = criterion(output, target) #将output与标签target比较,计算误差
optimizer.zero_grad() #清空梯度
loss.backward() #反向传播
optimizer.step() #一步随机梯度下降算法
right = rightness(output, target) #计算准确率所需数值,返回数值为(正确样例数,总样本数)
train_rights.append(right) #将计算结果装到列表容器train_rights中
if batch_idx % 100 == 0: #每间隔100个batch执行一次打印等操作
net.eval() # 给网络模型做标记,标志说模型在训练集上训练
val_rights = [] #记录校验数据集准确率的容器
'''开始在校验数据集上做循环,计算校验集上面的准确度'''
for (data, target) in validation_loader:
data, target = data.clone().requires_grad_(True), target.clone().detach()
output = net(data) #完成一次前馈计算过程,得到目前训练得到的模型net在校验数据集上的表现
right = rightness(output, target) #计算准确率所需数值,返回正确的数值为(正确样例数,总样本数)
val_rights.append(right)
# 分别计算在目前已经计算过的测试数据集,以及全部校验集上模型的表现:分类准确率
#train_r为一个二元组,分别记录目前已经经历过的所有训练集中分类正确的数量和该集合中总的样本数,
#train_r[0]/train_r[1]就是训练集的分类准确度,同样,val_r[0]/val_r[1]就是校验集上的分类准确度
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
#val_r为一个二元组,分别记录校验集中分类正确的数量和该集合中总的样本数
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
#打印准确率等数值,其中正确率为本训练周期Epoch开始后到目前撮的正确率的平均值
print(val_r)
print('训练周期: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\t训练正确率: {:.2f}%\t校验正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
#将准确率和权重等数值加载到容器中,以方便后续处理
record.append((100 - 100. * train_r[0] / train_r[1], 100 - 100. * val_r[0] / val_r[1]))
# weights记录了训练周期中所有卷积核的演化过程。net.conv1.weight就提取出了第一层卷积核的权重
# clone的意思就是将weight.data中的数据做一个拷贝放到列表中,否则当weight.data变化的时候,列表中的每一项数值也会联动
'''这里使用clone这个函数很重要'''
weights.append([net.conv1.weight.data.clone(), net.conv1.bias.data.clone(),
net.conv2.weight.data.clone(), net.conv2.bias.data.clone()])
最终训练效果:
(tensor(4886), 5000)
训练周期: 19 [57600/60000 (96%)] Loss: 0.081049 训练正确率: 98.00% 校验正确率: 97.72%
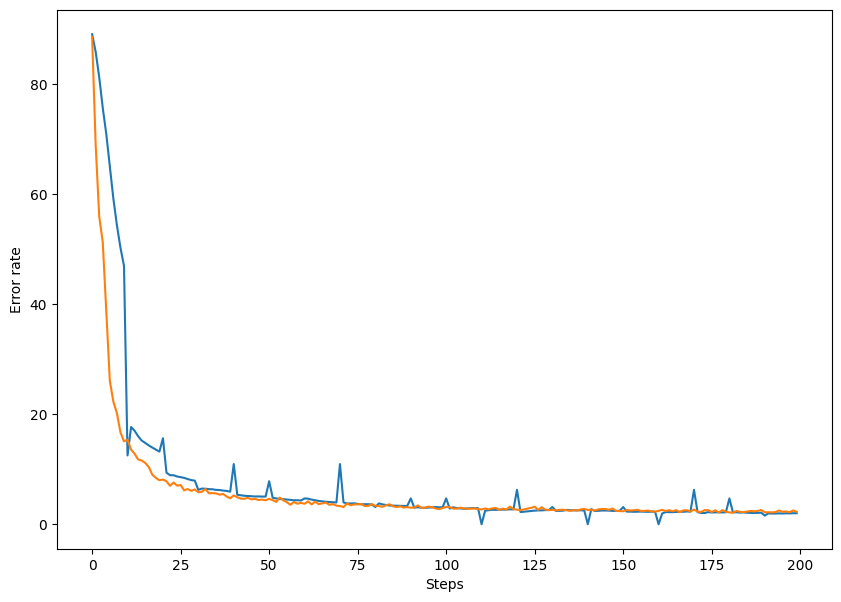
绘制训练曲线:
#绘制训练过程的误差曲线,校验集和测试集上的错误率。
plt.figure(figsize = (10, 7))
plt.plot(record) #record记载了每一个打印周期记录的训练和校验数据集上的准确度
plt.xlabel('Steps')
plt.ylabel('Error rate')
效果如下:
测试集测试
#在测试集上分批运行,并计算总的正确率
net.eval() #标志模型当前为运行阶段
vals = [] #记录准确率所用列表
#对测试数据集进行循环
for data, target in test_loader:
data, target = data.clone().detach().requires_grad_(True), target.clone().detach()
output = net(data) #将特征数据喂入网络,得到分类的输出
val = rightness(output, target) #获得正确样本数以及总样本数
vals.append(val) #记录结果
#计算准确率
rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
right_rate = 100. * rights[0].numpy() / rights[1]
print(right_rate)
输出测试集正确率:99.1
绘制第一层卷积核
#提取第一层卷积层的卷积核
plt.figure(figsize = (10, 7))
for i in range(4):
plt.subplot(1,4,i + 1)
plt.axis('off')
plt.imshow(net.conv1.weight.data.numpy()[i,0,...]) #提取第一层卷积核中的权重值,注意conv1是net的属性
plt.subplot(1,4,2)
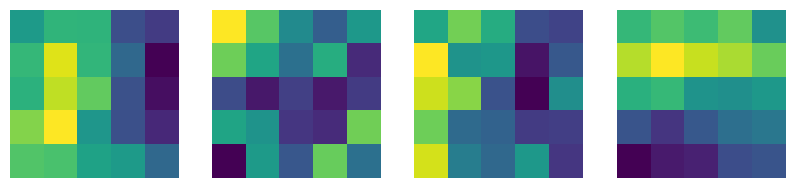
绘制第一层特征图
#调用net的retrieve_features方法可以抽取出喂入当前数据后吐出来的所有特征图(第一个卷积和第二个卷积层)
#首先定义读入的图片
#它是从test_dataset中提取第idx个批次的第0个图,其次unsqueeze的作用是在最前面添加一维,
#目的是为了让这个input_x的tensor是四维的,这样才能输入给net。补充的那一维表示batch。
input_x = test_dataset[idx][0].unsqueeze(0)
feature_maps = net.retrieve_features(input_x) #feature_maps是有两个元素的列表,分别表示第一层和第二层卷积的所有特征图
plt.figure(figsize = (10, 7))
#有四个特征图,循环把它们打印出来
for i in range(4):
plt.subplot(1,4,i + 1)
plt.axis('off')
plt.imshow(feature_maps[0][0, i,...].data.numpy())
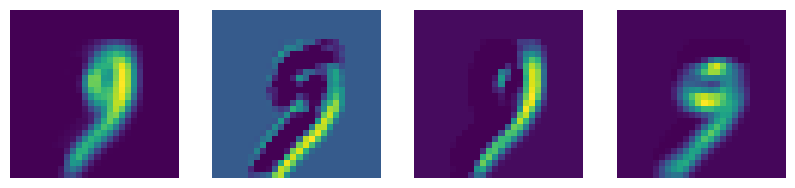
本文作者:Maeiee
本文链接:PyTorch 卷积神经网络
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
